Agents Need Feedback Loops, Not Just Knowledge Bases
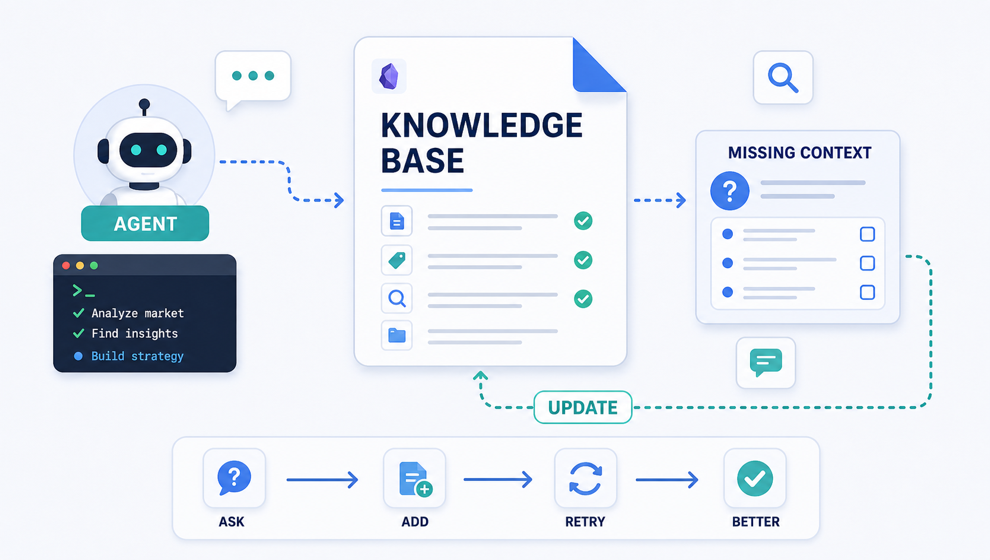
Since Andrej Karpathy shared his LLM Wiki pattern, many people have started connecting AI agents with Obsidian-style knowledge bases. The idea is strong: keep knowledge in a readable structure, let agents use it during their work, and make the system better over time.
A lot of teams and solo builders are already using this pattern to build small agent teams. And in many cases, it works surprisingly well. But I noticed one important limitation: this model works best when the user already knows exactly what information the agent needs and how that information should be processed.
That is often true in engineering. It is less true in marketing, research, strategy, or when you are exploring a new problem. In these areas, we often do not know in advance what context is missing. We give the agent what we have, ask it to reason, and then get frustrated when it makes a decision based on assumptions we did not expect.
We call it a hallucination. But often it is not just a hallucination. It is the agent reasoning from the information it had, plus the hidden assumptions already inside the model. The user expected one context. The agent used another.
So I think agents need a feedback loop. Every working agent should know where to ask for missing information. It can be a file, a Slack channel, a Telegram chat, or any other shared place. The important part is simple: when the agent does not have enough context, it should be able to say what is missing and request the data it needs.
Then the user adds that information to the knowledge base. On the next run, the agent does not start from the same blind spot. This is how we close another part of the context gap: not by hoping the agent guesses better, but by giving it a clear way to ask for the knowledge it does not yet have.